Dataframe에서 행을 sampling 하기 위해서는 axis = 1 을 사용한다. [ 거짓 ] → axis=1 (열 방향) axis=0 (행 방향)
5주차
5-1. 퀴즈
어떤 dataframe에서 'E'의 label을 갖는 column을 삭제하기 위해서 사용하는 명령어를 쓰시오. [ df.drop("E", axis=[1]) ]
dataframe에서결측값을 0으로바꾸는명령어는 "df.dropna(0)"이다. [ 거짓 ]
5-2. 퀴즈
dataframe df의 첫 10개의 행을 추출하는 명령어를 쓰시오. [ [df.head(10)] ]
dataframe df에서각열에대한평균을계산하는명령은 "df.average(0)"이다. [ 거짓 ]
5-3. 퀴즈
merge 함수를 이용해서 dataframe을 연결할 때 서로 일치하지 않는 key에 대해서는 [ 결측값 /NaN ] 이 발생한다.
서로다른차원의 dataframe들을연결하는 concat 함수에서공통된행과열에대해서만연결을수행하기위해서는 join의속성을 "inner"로설정해야한다. [ 거짓 ]
6주차
6-1. 퀴즈
웹 페이지가 저장하는 정보를 가져가도록 허용하는 서비스를 함수의 형태로 제공하는 것을 [ API ] 라고 한다.
웹페이지를 작성한 html 코드를 보고싶으면 control 키와 [ u ] 키를 동시에 누르면 된다.
6-2. 퀴즈
웹 페이지를 표현하는 html 문서를 가져오는 과정을 [ 웹 크롤링 ] 이라고 한다.
웹 페이지를 표현하는 문서를 가져와서 그 내용을 분석하는 과정을 [ 웹 스크레이핑 ]이라고 한다.
6-3. 퀴즈
"["와 "]" 사이에 들어있는 모든 문장을 표현하는 정규표현식은 무엇인가? [ r"[. ?]" ]
모든 영어 이름을 표현하는 정규표현식은 무엇인가? [ r"[A-Z][a-z]+" ]
6-4. 퀴즈
하나의 문자열을 이용해서 다른 문자열을 분리할 때 사용하는 정규 표현식 함수는? [ split ]
하나의 문자열이 다른 문자열에 포함되는 것을 점검하는 정규 표현식 함수는? [ match ]
7주차
7-1. 퀴즈
BeautifulSoup은 html 문서를 파싱하는 Python 모듈이다. [ 참 ]
BeautifulSoup에서 tag로 시작하고 끝나는 첫번째 문장을 찾는 함수는 select ( )이다. [ 거짓 ]
7-2. 퀴즈
BeautifulSoup에서 tag으로 묶이지 않은 문자열을 찾아주는 함수는 무엇인가? [ string ]
BeautifulSoup에서 tag로 시작하고 끝나는 모든 문장을 찾는 함수는 find ( )이다. [ 거짓 ]
7-3. 퀴즈
requests를 이용한 웹 크롤링에서 url로부터 html 문서를 추출하는 함수는 무엇인가? [ get ]
[div class="tab_list_wrap"] ~ [/div]으로 둘러쌓인 모든 문장을 추출하는 함수를 쓰시오. [ 답: soup.findall("div", {"class" : "tab_list_wrap"}) ]
7-4. 퀴즈
파이썬의 딕셔너리는 key와 [ value ] 의 조합으로 구성된 자료구조이다.
파이썬에서 한 리스트의 원소는 어떤 딕셔너리의 key 값으로 사용될 수 있다. [ 참 ]
중간고사
ㅠㅠ 문제 정리 못함 ㅠ
9주차
9-1. 퀴즈
회귀는 비지도 학습에 속하는 대표적인 기계학습 기법이다. [ 거짓 ]
집의 면적에 따라 집값을 예측하는 모델을 학습한다고 가정하자. 회귀의 관점에서 집의 면적을 부르는 용어로 적절한 것을 고르시오. [ Feature ]
9-2. 퀴즈
인공지능 기술의 기계학습 기술에서 중요한 구성 요소는 알고리즘(모델)과 데이터이다. [ 참 ]
인공지능 분야의 세 번째 봄을 가져다 준 기술은 object recognition 분야의 기술이다. [ 참 ]
10주차
10-1. 퀴즈
종양에 대한 데이터 x 로부터 그것인 악성인지(y=1, malignant) 아닌지(y=0, benign) 예측하고자 한다. 어떤 종양에 대해 우리가 만든 로지스틱 회귀 분류기가 h𝜃(x)=0.7 를 출력으로 계산했다. 이를 통해 우리는 그 종양이 악성일 확률이 70% 라고 추정한다. 그렇다면 이 종양이 악성이 아닐 확률 은 얼마로 추정할 수 있을까? a. P(y=0|x;𝜃) = 0.7×0.3 b. P(y=0|x;𝜃) = 0.7 c. P(y=0|x;𝜃) = 0.7의 제곱 ✅d. P(y=0|x;𝜃) = 0.3
특성 x를 통해 특정 카테고리를 예측하고자 한다. 이 작업을 로지스틱 회귀로 모델링할 때, 우리가 최소화해야 하는 함수는 다음 중 무엇인가? [ D ]
10-2. 퀴즈
의사결정 트리에서 자식 노드는 최대 2개까지 가질 수 있으며, 하나만 가지고 있어도 된다. [ 거짓 ]
의사 결정 트리의 생성 원칙 중, ‘한 node에서 child node로 분화할 경우 얻을 수 있는 무질서도(entropy)의 감소’를 [ 정보 획득 ] 이라 한다
10-3. 퀴즈
Precision과 recall은 다음과 같이 정의된다.
테스트 셋에 대한 본인 알고리즘의 성능이 아래와 같다.
이 알고리즘의 precision 과 recall 은? [ Precision=0.8, recall=0.5 ]
어린이 시청자를 위한 유익 동영상 분류기를 개발하고자 한다. 어린이에게는 유익한 영상을 몇 개 못 보더라도, 안전한 동영상만을 보여주는 것이 중요하다. 이 때 아래 보기 중 성능 측정 메트릭(metric)으로 적절한 것을 고르시오. [ Precision ]
11주차
11-1. 퀴즈
랜덤 포레스트(Random forest)는 앙상블 모델의 특수한 경우이다. [ 참 ]
랜덤 포레스트(Random forest)는 분류 문제에는 적용할 수 있지만, 회귀 문제에는 적용할 수 없다. [ 거짓 ]
11-2. 퀴즈
트리를 생성할 때 train set 의 부분 집합을 활용해서 트리를 생성하는 랜덤 포레스트 알고리즘의 방법 [ Bagging ]
한 모델의 결과에서 도출된 오류를 다른 모델을 이용해 보정하여 최종 결과를 도출하는 랜덤 포레스트 알고리즘의 방법 [ Boosting ]
11-3. 퀴즈
앙상블 모델에서는 여러 모델들을 이용하여 결과를 도출한다. 이 때 사용하는 모델들은 학습되는 데이터셋은 달라도 되지만, 모델들은 동일한 종류를 사용해야 한다. [ 거짓(false) ]
Bagging 알고리즘의 입력을 고르시오. ✅a. 데이터셋 L b. 오류를 통해 보완된 f’ c. 오류를 통해 보완된 데이터셋 L’ d. 모델 f
11-4. 퀴즈
Bagging 알고리즘의 출력을 고르시오. ✅a. 모델 f b. 오류를 통해 보완된 데이터셋 L’ c. 오류를 통해 보완된 f’ d. 데이터셋 L
그림에서 B가 의미하는 것을 고르시오. ✅a. 데이터셋 L의 일부를 샘플링한 부분집합의 개수 b. 데이터셋 L의 원소의 개수 c. 최종 결정 모델 d. 데이터셋 L의 일부를 샘플링한 원소의 개수 e. 오류를통해보완된데이터셋 L’ 의원소의개수
12주차
12-1. 퀴즈
Bagging 알고리즘에서, N개의 데이터를 가진 모집단에서 원소 하나가 선택되지 않을 확률은 1 - 1/N 이다. 하지만 샘플링 횟수를 무한히 늘린다면, 확률적으로 원소 하나가 선택되지 않을 확률은 0에 가깝다. 즉 모든 원소가 빠짐없이 다 선택된다는 의미이다. [ 거짓(false) ]
kc_hous_data 에서 집 가격에 영향을 덜 미치는 속성을 모두 고르시오. ✅ a. data ✅ b. id ✅ c. zipcod d. number of bedrooms
12-2. 퀴즈
다음은 Adaboost의 strong classifier가 week classifier를 이용하여 최종 결정을 내리는 식이다.이 식에 따르면, weak classifier 앞에 곱해지는 alpha 값이 작은 경우, 해당 weak classifier 의 결정을 무시하는 효과를 가진다. [ 참(true) ]
다음은 Adaboost 알고리즘이다. 위 (1), (2), (3)에들어가는다음보기에서골라적절히순서대로배치하시오. [ A-C-B ]
13주차
13-1. 퀴즈
기계학습의 세 가지 패러다임은 지도학습, 비지도학습, 강화학습이 있다. [ 참(true) ]
비지도학습이란 레이블이 없는 데이터의 패턴을 학습하는 알고리즘 유형이다.[참(true) ]
차원축소란 효율적인 예측이 가능하도록 지나치게 많은 데이터의 속성을 줄이는 작업이다.[참(true) ]
다음 중 '다양한 데이터의 속성 중에서 속성 간의 상관 관계를 이용해서 데이터의 속성을 줄이는 기법'을 고르세요. a. Feature selection b. Information Gain Odds ratio ✅ c. Principal component analysis d. t-SNE e. Multi-dimensional scaling
14주차
14-1. 퀴즈
RNN의 학습에서는 CNN의 학습과 달리 시간 혹은 순서를 고려해야 한다. [ 참(true) ]
RNN(Recurrent neural network) 에 적용될 수 있는 데이터는 무엇인가? 1. 주식 데이터 ✅ 2. 모두 3. 날짜별 평균 온도 4. 음성 데이터 5. 텍스트 데이터
14-2. 퀴즈
RNN(Recurrent neural network) 구조는 텍스트 데이터 이 외 데이터에는 적용할 수 없다. [ 거짓(false) ]
연속 데이터와 시계열 데이터를 구분 짓는 기준은 '순서'와 정보의 차이이다. [ 거짓(false) ]
14-3. 퀴즈
일대다(one to many) 타입의 RNN 구조는 자연어 생성, 기계번역 등에 활용된다. [ 참(true) ]
자연어 생성은 bidirectional RNN을 사용하여 해결한다.[ 거짓(false) ]
14-4. 퀴즈
Long short-term memory (LSTM)은 그라디언트 소실(gradient vanishing) 문제를 해결하기 위해 제안되었다. [ 참(true) ]
다음과 같은 single-layered RNN의 input tensor의 shape으로 알맞는 것을 고르시오.
(이론 시간 설명을 기준으로 하시오. 단, n:단어의 개수, input_size:단어 한개를 표현하는 벡터의 차원의 수, hidden_size: hidden state 벡터의 차원의 수, batch_size: 한 번에 GPU 에서 처리하는 데이터의 개수)
하나를 선택하세요. a. (batch_size, n, hidden_size) b. (batch_size, input_size, n) c. (input_size, batch_size, n) ✅d. (batch_size, n, input_size) e. (n, batch_size, input_size)
15주차 기말고사
회귀/분류 모델의 overfitting과 underfitting을 다 피하기 위해서는 복잡한 모델을 사용하면서 높은 차수의 변수를 무시할 수 있도록 ✅ 정규화 를 적용한다.
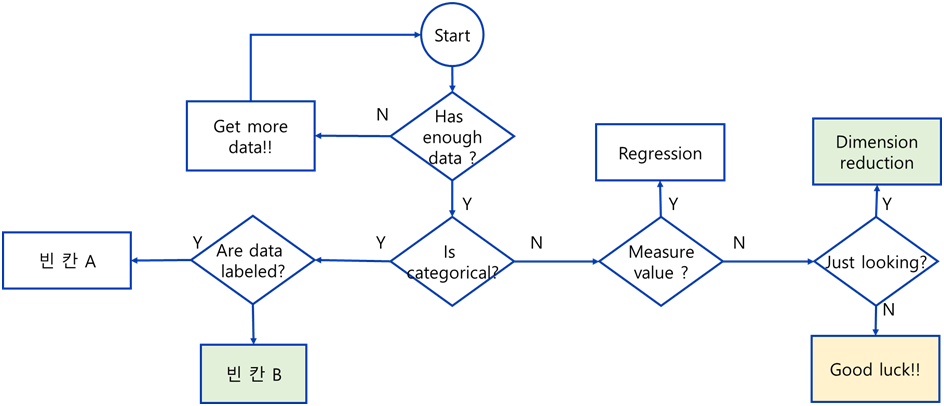
다음 그림에서 빈칸 A, B를 순서대로 채우시오.
빈칸 A : ✅ Classification
빈칸 B : ✅ Clustering
의사 결정 트리에서 정보 획득은 한 node에서 child node로 분화할 경우 얻을 수 있는 ❌ 불순도 의 감소를 의미한다.
Ensemble model에서 각 모델의 결과를 다시 훈련 데이터로 활용하여 학습한 모델을 이용해서 최종 결과를 도출하는 기법을❌ 스태킹 이라고 한다.
중복을 허용하지 않는 샘플링 기법을 통해서 표본을 수집하는 방법을 ❌ 페이스 이라고 한다.
여러 개의 weak learner를 순차적으로 결합하여 예측 성능을 향상시키는 기법인 boosting 기법 중에서 각 데이터에 각각 다른 가중치를 적용해서 예측을 수행하는 기법 두 가지는 ❌ AdaBoost, LogitBoost 이라고 한다.
차원 축소 기법들 중에서 PCA는 ✅ 분산 에 기반한 기법이다.
다음 중 로지스틱 회귀의 loss 함수에 대한 설명으로 잘못된 것을 고르시오. ✅ a. gradient descent의 적용이 쉬워야하기 때문에 함수의 모양이 concave해야 한다. b. ground truth는 0또는 1의 값만을 갖는다. c. cross entropy loss라고 한다. d. 함수의 미분이 쉬워야 한다.
다음 중 로지스틱 회귀의 loss 함수에 대한 설명으로 잘못된 것을 모두 고르시오. a. cross entropy loss라고 한다. ❌ b. gradient descent의 적용이 쉬워야하기 때문에 함수의 모양이 concave해야한다. c. 함수의 미분이 쉬워야 한다. d. ground truth는 0또는 1의 값만을 갖는다.
Bagging model에서 P(OOB)를 쓰시오. → ❌36.8%
아래 식에서 로지스틱 회귀 모델의 식으로 적절한 것을 고르시오. → ✅ A
아래 그림은 Bagging 알고리즘에 대한 설명을 위한 그림이다. 이 그림에서 B가 의미하는 것을 고르시오
a. 데이터셋 L의 원소의 개수 ❌b. 데이터셋 L의 일부를 샘플링한 원소의 개수 c. 오류를 통해 보완된 데이터셋 L'의 원소의 개수 d. 데이터셋 L의 일부를 샘플링한 부분집합의 개수 e. 최종 결정 모델
종양에 대한 데이터 x 로부터 그것인 악성인지(y=1, malignant) 아닌지(y=0, benign) 예측하고자 한다. 어떤 종양에 대해 우리가 만든 로지스틱 회귀 분류기가 h𝜃(x)=0.8 를 출력으로 계산했다. 이를 통해 우리는 그 종양이 악성일 확률이 80% 라고 추정한다. 그렇다면 이 종양이 악성이 아닐 확률 은 얼마로 추정할 수 있을까? ✅a. P(y=0|x;𝜃) = 0.2 b. P(y=0|x;𝜃) = 0.8 c. P(y=0|x;𝜃) = 0.8×0.2 d. P(y=0|x;𝜃) = 0.82
RNN(Recurrent neural network)에 적용될 수 있는 데이터는 무엇인가? a. 주식 데이터 ✅b. 모두 c. 음성 데이터 d. 텍스트 데이터
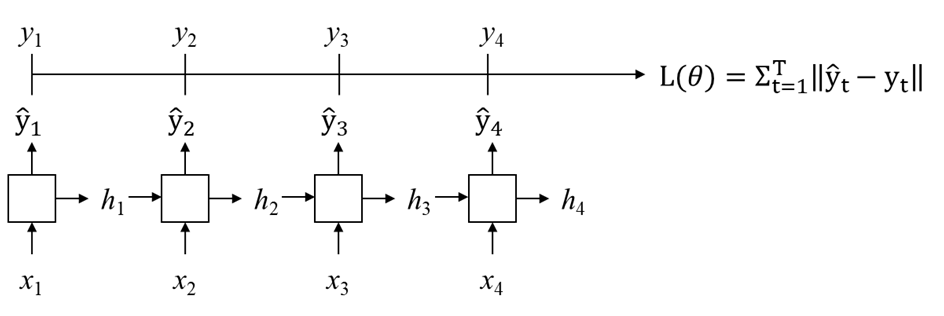
아래 그림과 같은 RNN 구조에 대한 설명으로 옳은 것을 모두 고르시오. 하나 이상을 선택하세요.
a. 이 그림에서 레이어는 총 4개이다. ✅b. Multi-layered RNN 구조이다. c. 이 구조의 은닉 상태(hidden state)는 모든 레이어의 은닉 상태를 말한다. d. 서로 다른 레이어에서는 같은 θ를 공유한다. ✅e. 시간 축에 대해서는 같은 θ를 공유한다. ✅f. 마지막 레이어의 은닉 상태(hidden state)는 우리가 예측하려는 출력값이다.